2 Methodology
2.1 Technical design
2.1.1 Research strategy
A quantitative analysis of the road connectivity and access to healthcare facilities before and after a flooding event identified the temporal patterns of changes on centrality metrics. This was based on the case study of Rio Grande do Sul floodings that took place in late April 2024. The spatial pattern of the flooding shown that some regions were more vulnerable than others. Lastly, an assessment of different pathways to the healthcare facilities contributed to take an informed decision on which areas are more critical to avoid the disruption of healthcare access facilitating urban resilience.
Therefore, this practical-orientated research aim to make a diagnosis of the occurred flooding in Rio Grande do Sul to identifying the potential critical infrastructures necessary for accessing healthcare facilities that could improve the urban resilience against future floodings.
2.1.2 Research planning
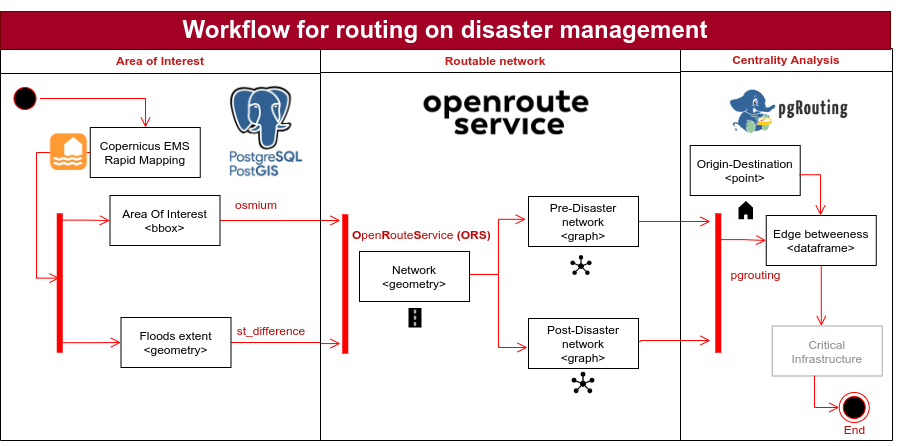
To address the diagnosis of the loss of centrality by the flooding, the methodological approach is segmented into three major lanes that constituted the workflow of this research.
- The first lane, selection of the Area Of Interested (AOI), defined the study area based on the flooding extent reported by the Universidade Federal do Rio Grande do Sul and imported the OSM network geometry using osmium.
- The second lane, routable network, transformed the OSM network geometry into a routable graph network using OpenRoutService. Additionally, the post-disaster network is derived through spatial overlay with the extent of flooding.
- The third lane,centrality analysis , connectivity and accessibility metrics identified critical infrastructure.
The method is based on PostgreSQL using the extensions PostGIS and Pgrouting. In the context of emergency management, the spatial database PostGIS and the library of functions Pgrouting proved to be useful developing emergency notifications (Hataitara, Piyathamrongchai, and Choosumrong 2024) or finding dynamic shortest simulating obstruction of the network by floods (Singh et al. 2015), (Choosumrong et al. 2019).
2.1.3 Research material
The before and after flooding networks are obtained using the OSM network from Geofabrik and the flooding extent from Universidad de Rio Grande do Sul. Regarding the location of the hospitals, the Geoportal de Rio Grande do Sul and OSM offered this data. From this material, the PostGIS and OpenRouteService Docker set up the environment required to conduct the centrality analysis. Moreover, the Global Settlement Layer-SMOD classified the different cities to select the AOI, while the Global Settlement -Bult-V added different weights used in the origin-destination sampling. This research material is shown in the table.
3 Workflow
3.1 Selecting the Area of Interest (AoI) and importing data
PostGIS queries obtained the Area of Interest calculating the bounding box from the flooding extent provided by the Universidade Federal do Rio Grande do Sul. Likewise, PostGIS queries prepared the flooding extent for the analysis subdividing the layer and removing slivers. Having obtained the area of interest, the C++/Javascript framework osmium (Barron, Neis, and Zipf 2014) processed the OSM data obtaining the geometry of the network.
3.1.1 Importing data into PostgreSQL
The tool ogr2ogr imported the data into a PostgreSQL database. The output file format parameter -f included the PostgreSQL connection components, while the parameters -nln and -lco assigned the name of the table and columns respectively. For the OSM network, the parameter -nlt adjusted the multilinestring geometry to linestring to process single features more efficiently as indicated in the bibliography (Obe and Hsu 2017).
PostGIS: Importing data to PostgreSQL using ogr2ogr
## OSM geometry: porto_alegre_net_pre.geojson
ogr2ogr -f PostgreSQL PG:"host=localhost port= 25432 user=docker password=docker dbname=gis schemas=heigit" /home/ricardo/HeiGIT-Github/data_required_porto_alegre/porto_alegre_net_pre.geojson -nln porto_alegre_net_pre -lco GEOMETRY_NAME=the_geom -nlt LINESTRING -explodecollections
## Administrative units: nuts.geojson
ogr2ogr -f PostgreSQL PG:"host=localhost port= 25432 user=docker password=docker dbname=gis schemas=heigit" /home/ricardo/HeiGIT-Github/data_required_porto_alegre/nuts.geojson -nln nuts -lco GEOMETRY_NAME=geom
## Flooding extent: flooding_rio_grande_do_sul.geojson
ogr2ogr -f PostgreSQL PG:"host=localhost port= 25432 user=docker password=docker dbname=gis schemas=heigit" /home/ricardo/HeiGIT-Github/data_required_porto_alegre/flooding_rio_grande_do_sul.geojson -nln flooding_rio_grande_do_sul -lco GEOMETRY_NAME=the_geom
## Building density: urban_center_4326.geojson
ogr2ogr -f PostgreSQL PG:"host=localhost port= 25432 user=docker password=docker dbname=gis schemas=heigit" /home/ricardo/HeiGIT-Github/data_required_porto_alegre/urban_center_4326.geojson -nln urban_center_4326 -lco GEOMETRY_NAME=geom
## Hospitals
### From Rio Grande do Sul Geoportal
ogr2ogr -f PostgreSQL PG:"host=localhost port= 25432 user=docker password=docker dbname=gis schemas=heigit" /home/ricardo/HeiGIT-Github/data_required_porto_alegre/Hospitais_com_Leitos_de_UTIs_no_RS.geojson -nln hospitals_bed_rs -lco GEOMETRY_NAME=geom3.1.2 Preparing the flooding mask
The downloaded flooding extent covered a larger area in Rio Grande do Sul. However, the area of interest that contained urban dense cities such as Porto Alegre was smaller. Therefore, a series of operations reduced the area focusing on Porto Alegre and at the same time improved the query performance.
Subdividing the flooding mask to make the spatial indexes more efficient was the first step. The reason was the higher number of vertices of large objects and larges bounding boxes that hinder the spatial index performance (Link). After enabling the spatial indexes, selecting only the flooding subunits that intersected with the area of interest reduced the size of the region query. Previous studies reported that reducing the number of spatial polygons and points of the region saved processing time and computation costs (Zhao et al. 2017). Additionally, the following code dissolved the borders to break the multipolygon into simple polygons to improve the performance of functions such as st_difference() and removed slivers polygons. Based on size criteria, the calculated area of these undesirable polygons identified the slivers of the flooding extent (Grippa et al. 2018). (link).
PostGIS: Subdiving flooding extent and removing slivers
--- 1) Subdividing to make spatial indexes more efficent
--- Select the GHS area that intersects with Porto Alegre
CREATE TABLE flooding_subdivided_porto AS
WITH porto_alegre_ghs AS(
SELECT
ghs.*
FROM
urban_center_4326 AS ghs
JOIN
nuts
ON
st_intersects(nuts.geom, ghs.geom)
WHERE
nuts.shapename = 'Porto Alegre'),
--- Bounding Box that contained the GHS in Porto Alegre
porto_alegre_ghs_bbox AS(
SELECT
st_setsrid(st_extent(geom),4326) as geom_bbox
FROM
porto_alegre_ghs),
---Subdivide the flood extent to increase spatial indexes performance
flooding_sul_subdivided AS (
SELECT
st_subdivide(geom) as the_geom
FROM
flooding_rio_grande_do_sul)
---- Select the flooding subunits that intersects with the previous bounding box
SELECT
flooding_sul_subdivided.*
FROM
flooding_sul_subdivided,
porto_alegre_ghs_bbox
WHERE
st_intersects(flooding_sul_subdivided.the_geom, porto_alegre_ghs_bbox.geom_bbox);
--- 2) Simplifying geometry
CREATE TABLE flooding_cleaned_porto AS
SELECT
(ST_Dump(the_geom)).geom::geometry(polygon, 4326) geom
FROM
flooding_subdivided_porto;
CREATE TABLE flooding_cleaned_porto_union AS
SELECT
ST_Union(geom)::geometry(multipolygon, 4326) geom
FROM
flooding_cleaned_porto;
CREATE TABLE flooding_cleaned_porto_union_simple AS
SELECT
(ST_Dump(geom)).geom::geometry(polygon, 4326) geom
FROM
flooding_cleaned_porto_union;
--- This allowed to calculate the area of each polygon finding slivers that were removed using the following code.
SELECT COUNT(*)
FROM flooding_cleaned_porto_union_simple ; --- count= 54.
DELETE FROM
flooding_cleaned_porto_union_simple
WHERE
ST_Area(geom) < 0.0001; ---count= 2.
--- Obtain Area
SELECT
sum(st_area(geom::geography)/10000)::integer
FROM
flooding_cleaned_porto_union_simple;
--- Obtain size in memory
SELECT
pg_size_pretty(SUM(ST_MemSize(geom)))
FROM
flooding_cleaned_porto_union_simple;
--- Obtain number of points
SELECT
sum(ST_Npoints(geom))
FROM
flooding_cleaned_porto_union_simple;3.2 Obtaining pre and post disaster routable networks
The creation of the network after the disaster using the modified flooding mask and the creation of the origin-destination are considered in this section. Before generating these routable networks, the following code set configuration parameters, recommended to deliver faster results (Jhummarwala Abdul 2014).
PostGIS: Adjusting configuration settings
--- Set up the configuration
----- Increase performance by using more max_parallel_workes_per_gather (https://blog.cleverelephant.ca/2019/05/parallel-postgis-4.html)
SET max_parallel_workers_per_gather =4;
----- Cluster the index (https://gis-ops.com/pgrouting-speedups/)
CLUSTER porto_alegre_net_largest USING porto_alegre_net_largest;3.2.1 Importing OpenStreetMap (OSM) network as geometry
The following SQL code created the command to import OpenStreetMap (OSM) network using osmium. After creating the spatial index on the network table, the GHS-SMOD dataset the Global Human Settlement that intersected with Porto Alegre is selected as AOI. Secondly, this GHS is used to dynamically generate the bounding box and command line required by osmium. The OSM network obtained with this osmium command was the input required for OpenRouteService (ORS).
PostGIS: Generating responsive code to import OSM
--- 0) Add spatial index everywhere:
CREATE INDEX idx_porto_alegre_net_largest_geom ON porto_alegre_net_largest USING gist(the_geom);
CREATE INDEX idx_porto_alegre_net_largest_source ON porto_alegre_net_largest USING btree(fromid);
CREATE INDEX idx_porto_alegre_net_largest_target ON porto_alegre_net_largest USING btree(toid);
CREATE INDEX idx_porto_alegre_net_largest_id ON porto_alegre_net_largest USING btree(ogc_fid);
CREATE INDEX idx_porto_alegre_net_largest_cost ON porto_alegre_net_largest USING btree(weight);
--- 1) GHS urban area that intersected with Porto Alegre city
WITH porto_alegre_ghs AS(
SELECT
ghs.*
FROM
urban_center_4326 AS ghs
JOIN
nuts
ON
st_intersects(nuts.geom, ghs.geom)
WHERE
nuts.shapename = 'Porto Alegre'),
--- Bounding Box that contained the GHS in Porto Alegre
porto_alegre_ghs_bbox AS(
SELECT
st_setsrid(st_extent(geom),4326) as geom_bbox
FROM
porto_alegre_ghs),
--- 2) The command used the Porto Alegre GHS and its Bounding Box to import the OpenStreet Network.
porto_alegre_ghs_bbox_osmium_command AS (
SELECT
ST_XMin(ST_SnapToGrid(geom_bbox, 0.0001)) AS min_lon,
St_xmax(ST_SnapToGrid(geom_bbox,0.0001)) AS max_lon,
St_ymin(ST_SnapToGrid(geom_bbox,0.0001)) AS min_lat,
St_ymax(ST_SnapToGrid(geom_bbox, 0.0001)) AS max_lat
FROM porto_alegre_ghs_bbox)
SELECT
'osmium extract -b '
|| min_lon || ',' || min_lat || ',' || max_lon || ',' || max_lat ||
' sul-240501.osm.pbf -o puerto_alegre_urban_center.osm.pbf' AS osmium_command
FROM porto_alegre_ghs_bbox_osmium_command;3.2.2 Transforming geometric network into routable graph network using OpenRouteService (ORS).
Firstly, running the docker for OpenRouteService transformed the OSM network from the GHS AoI into a graph. In the “ors-config.yml” from OpenRotueService (ORS), the “source_file” parameter is set to find the directory that contained the OSM geometry network. OpenRouteService (ORS) created a a routable network assigining costs and adding information for each node such as the origin, “fromId”, and the destination, “toId”. The R script “get_graph” from Marcel Reinmuth exported the ORS network named as “porto_alegre_net”.
Secondly, the data type of the columns “fromid” and “toid” from the graph network generated by ORS is transform into bigint to run the algorithm pgr_dijkstra as the official documentation indicated.
PostGIS: Adjusting ORS configuration & preparation for pgrouting
--- 1) the source_file parameter in the ors.config.yml file is set to find the imported OSM network
source_file: /home/ors/files/puerto_alegre_urban_center.osm.pbf
---- 2) The exported ORS graph is prepared for pgrouting casting the right data type for the pgrouting functions.
select * from porto_alegre_net_pre;
ALTER TABLE porto_alegre_net_pre
ALTER COLUMN "toid" type bigint,
ALTER COLUMN "fromid" type bigint,
ALTER COLUMN "ogc_fid" type bigint;R: Visualizing OSM and ORS network with Mapview
## Load data
ors_network <- st_read(eisenberg_connection, layer="porto_alegre_net_pre")
osm_network <- st_read(eisenberg_connection, layer="puerto_alegre_ghs_osm")
ors_network_subset <- ors_network |> head()
## Create subset using a bounding box
ors_subset <- ors_network |> filter(id ==140210) |> st_bbox()
xrange <- ors_subset$xmax - ors_subset$xmin
yrange <- ors_subset$ymax - ors_subset$ymin
## Expand the bounding box
ors_subset[1] <- ors_subset[1] - (4 * xrange) # xmin - left
ors_subset[3] <- ors_subset[3] + (4 * xrange) # xmax - right
ors_subset[2] <- ors_subset[2] - (2 * yrange) # ymin - bottom
ors_subset[4] <- ors_subset[4] + (2 * yrange) # ymax - top
## Convert bounding box into polygon
ors_subset_bbox <- ors_subset %>% #
st_as_sfc()
## Use the polygon to subset the network
intersection_ors <- sf::st_intersection(ors_network, ors_subset_bbox)
intersection_osm <- sf::st_intersection(osm_network, ors_subset_bbox)
## Mapview maps
m1 <- mapview(intersection_osm,
color="#6e93ff",
layer.name ="OpenStreetMap - Geometry",
popup=popupTable(intersection_osm,
zcol=c("id","osm_id","name","geom")))
m2 <- mapview(intersection_ors,
color ="#d50038",
layer.name="OpenRouteService -Graph",
popup=popupTable(intersection_ors))
sync(m1,m2) 3.2.3 Exploring ORS graph network and components
Before using the graph network, a quick inspection using the pgrouting function pgr_strongComponents() revealed the number of components or isolated self-connecting networks within the graph. The largest network component is selected using its length. The following code created a table with the different components and another table containing the largest component. The reason to discard the rest of components was its relatively small size and based on the observation that some of these components appeared next to OSM objects categorized as “barriers”, which meant that they were part of private properties, such as “Villa’s Home Resot”, being not relevant for an emergency response.
PostGIS: Obtaining components of the network and their length
--- 1) Quick inspection of the graph to determine components
---- Create a vertice table for pgr_dijkstra()
SELECT
pgr_createVerticesTable('porto_alegre_net_pre', source:='fromid', target:='toid');
---- Add data to the vertices created table
CREATE TABLE component_analysis_network_porto AS
WITH porto_alegre_net_component AS (
SELECT
*
FROM
pgr_strongComponents('SELECT ogc_fid AS id,
fromid AS source,
toid AS target,
weight AS cost
FROM
porto_alegre_net_pre')),
porto_alegre_net_component_geom AS (
SELECT
net.*,
net_geom.the_geom
FROM
porto_alegre_net_component AS net
JOIN
porto_alegre_net_pre AS net_geom
ON
net.node = net_geom.fromid)
SELECT
component,
st_union(the_geom) AS the_geom,
st_length(st_union(the_geom)::geography)::int AS length
FROM
porto_alegre_net_component_geom
GROUP BY component
ORDER BY length DESC;
--- 2) A table with the component of the network with the highest length
CREATE TABLE porto_alegre_net_largest AS
---- Obtain again table classifying nodes in different components
WITH porto_alegre_net_component AS (
SELECT
*
FROM
pgr_strongComponents('SELECT
ogc_fid AS id,
fromid AS source,
toid AS target,
weight AS cost
FROM
porto_alegre_net_pre')),
--- Calculate the largest component from the network
largest_component_net AS (
SELECT
component
FROM
component_analysis_network_porto
LIMIT 1),
--- Using the largest component from the network to filter
largeset_component_network_porto AS (
SELECT
*
FROM
porto_alegre_net_component,
largest_component_net
WHERE
porto_alegre_net_component.component = largest_component_net.component)
SELECT
net_multi_component.*
FROM
porto_alegre_net_pre AS net_multi_component,
largeset_component_network_porto AS net_largest_component
WHERE
net_multi_component.fromid IN (net_largest_component.node);R: Visualizing the three longest component
component_analysis_network <- st_read(eisenberg_connection, "component_analysis_network_porto")
## Select top 3
component_analysis_network_3 <- component_analysis_network |> arrange(desc(round(distance))) |> slice(1:3)
### Tidy component to be used as categorical variable
component_analysis_network_3$component <- component_analysis_network_3$component |> as.character() |> as_factor()
## Visualization
m1_net <- component_analysis_network_3 |>
filter(component=="1") |>
mapview(layer.name = "1st Longest component",
lwd= 0.5,
color="#66c2a5")
m2_net <- component_analysis_network_3 |>
filter(component=="3728") |>
mapview(layer.name = "2nd Longest component",
color ="#8da0cb",
lwd=3,
popup= popupTable( component_analysis_network_3[2,],
zcol=(c("component","distance"))))
m3_net <- component_analysis_network_3 |>
filter(component=="40578") |>
mapview(layer.name = "3rd Longest component",
color="#fc8d62",
popup= popupTable(component_analysis_network_3[3,]),
lwd =3)
m1_net + m2_net + m3_net3.2.4 Generating a routable pre-disaster network
The original porto_alegre_net_pre graph network is classified by its components and the largest component representing the network before the flooding is filtered.In the first step, the components are calculated and the vertices from the largest network stored in the table largeset_component_network_porto. Then, selecting the vertices from the original table where they also appeared in the largest component network generated the pre-disaster network.
PostGIS: Creating the pre-disaster network filtering out components
CREATE TABLE porto_alegre_net_largest AS
---- 1) Classify the geometric OSM network in different components
WITH porto_alegre_net_component AS (
SELECT
*
FROM
pgr_strongComponents('SELECT id,
source,
target,
cost
FROM
porto_alegre_net_pre')),
--- Obtaining the nodes from the largest component from the network
largest_component_net AS (
SELECT
component
FROM
component_analysis_network_porto
LIMIT 1),
--- 2) Filtering the nodes from the original network to only those in the largest component
largeset_component_network_porto AS (
SELECT
*
FROM
porto_alegre_net_component,
largest_component_net
WHERE
porto_alegre_net_component.component = largest_component_net.component)
SELECT
net_multi_component.*
FROM
porto_alegre_net_pre AS net_multi_component,
largeset_component_network_porto AS net_largest_component
WHERE
net_multi_component.source IN (net_largest_component.node);3.2.5 Generating a routable post-disaster network
A naive approach overlaying the flooding mask with the road network by the function st_difference() crashed the session. The follwing multi-step methodology reduced the processing cost making the query feasible using less resources by incorporating boolean operators in some steps. In other studies, decomposing difference function queries using boolean operators reported an increase on the performance of 223% in PostgreSQL (Lupa and Piórkowski 2014). Firstly the network inside the flooding mask is selected. Secondly, a subset of the network outside the flooding mask avoided using spatial operations saving computing resources by using the ID’s from the network inside the flooding to filter the data.Thirdly, to obtain the boundaries between the inside and outside network, the geometry is converted into its exterior ring. From this network on the boundary, only the exterior part that intersected with the outside boundary was selected.
PostGIS: Multi-step methodology to create the post-disaster network
--- 1) Network inside the flooding mask
CREATE TABLE porto_alegre_street_in_v2 AS
SELECT net.id,
CASE
WHEN ST_Contains(flood.the_geom, net.the_geom)
THEN net.the_geom
ELSE st_intersection(net.the_geom, flood.the_geom)
END AS geom
FROM porto_alegre_net_largest net
JOIN flooding_subdivided_porto flood
ON st_intersects(net.the_geom, flood.the_geom);
--- 2) Network outside the flooding mask
CREATE TABLE porto_alegre_street_out_v2 AS
SELECT net.*
FROM porto_alegre_net_largest net
WHERE net.id NOT IN (
SELECT net.id
FROM porto_alegre_street_in_v2 net);
--- 3) Network on the boundaries
CREATE TABLE porto_alegre_net_outside_v2 AS
WITH porto_alegre_ghs AS(
SELECT
ghs.*
FROM
urban_center_4326 AS ghs
JOIN
nuts
ON
st_intersects(nuts.geom, ghs.geom)
WHERE
nuts.shapename = 'Porto Alegre'),
--- Bounding Box that contained the GHS in Porto Alegre
porto_alegre_ghs_bbox AS(
SELECT
st_setsrid(st_extent(geom),4326) as geom_bbox
FROM
porto_alegre_ghs),
flooding_sul_subdivided AS (
SELECT
st_subdivide(geom) as the_geom
FROM
flooding_rio_grande_do_sul),
exterior_ring_porto_alegre_v2 AS (
SELECT
ST_ExteriorRing((ST_Dump(union_geom)).geom) as geom
FROM (
SELECT
ST_Union(flood.the_geom) as union_geom
FROM
porto_alegre_ghs_bbox as bbox
JOIN
flooding_sul_subdivided as flood
ON
ST_Intersects(flood.the_geom, bbox.geom_bbox)
) AS subquery)
SELECT net.id,
CASE
WHEN NOT ST_Contains(flood.geom, net.the_geom)
THEN net.the_geom
ELSE st_intersection(net.the_geom, flood.geom)
END AS geom,
net.target,
net.source,
cost,
"unidirectid",
"bidirectid"
FROM
porto_alegre_net_largest AS net
JOIN exterior_ring_porto_alegre_v2 flood ON
st_intersects(net.the_geom, flood.geom);
---- For the network
CREATE INDEX idx_porto_alegre_net_outside_v2 ON porto_alegre_net_outside_v2 USING gist (geom);
CLUSTER porto_alegre_net_outside_v2 USING idx_porto_alegre_net_outside_v2;
--- For the flooding mask
CREATE INDEX flooding_sul_subdivided_idx ON flooding_sul_subdivided USING gist (the_geom);
CLUSTER flooding_sul_subdivided USING flooding_sul_subdivided_idx;
---- Before doing difference
VACUUM(FULL, ANALYZE) porto_alegre_net_outside_v2;
VACUUM(FULL, ANALYZE) flooding_sul_subdivided;
--- st_difference and uniting the external to the boundaries
--- Unite the subunits of the flooding
CREATE TABLE flooding_symple as
SELECT st_union(geom) as the_geom FROM flooding_cleaned_porto_union_simple;
---- Index the flooding
CREATE INDEX flooding_symple_idx ON flooding_symple USING gist (the_geom);
CLUSTER flooding_symple USING flooding_symple_idx;
--- 4) Obtain the boundary network that intersect with the outside network
CREATE TABLE difference_outside_flood_v3 AS
SELECT net.id,
target,
source,
cost,
unidirectid,
bidirectid,
st_difference(net.geom, flood.the_geom) AS the_geom
FROM porto_alegre_net_outside_v2 AS net,
flooding_symple AS flood;
--- 5) Unite outside network with the external part of the boundary network
CREATE TABLE porto_alegre_net_post_v5 AS
SELECT *
FROM porto_alegre_street_out_v2
UNION
SELECT *
FROM difference_outside_flood_v3;R: Visualizing the multi-step methodology
porto_alegre_net_pre <- sf::st_read(eisenberg_connection, "porto_alegre_net_largest")
centrality_pre <- sf::st_read(eisenberg_connection, "centrality_weighted_100_bidirect_cleaned")
flooding <- sf::st_read(eisenberg_connection, "flooding_cleaned_porto")
net_in <- sf::st_read(eisenberg_connection, "porto_alegre_street_in_v2")
## subset
subset_network_pre <- sf::st_read(eisenberg_connection, "porto_alegre_net_largest_subset")
subset_network_in <- sf::st_read("/home/ricardo/heigit_bookdown/data/porto_alegre_street_in_v3_subset.geojson") |> select("geometry")
subset_network_out <- sf::st_read("/home/ricardo/heigit_bookdown/data/porto_alegre_street_out_subset.geojson")
subset_network_outside_flood <-sf::st_read("/home/ricardo/heigit_bookdown/data/porto_alegre_street_outside_subset.geojson")
subset_network_post <- sf::st_read(eisenberg_connection, "reet_united_v3")
flooding <- sf::st_read(eisenberg_connection, "flooding_symple") |> st_as_sf()
## centrality
mapview(subset_network_pre,
color="#d4e7e7",
lwd= 1,
layer.name="0.Pre-flooding network",
popup=popupTable(subset_network_pre,
zcol=c("id","source","target","bidirectid"))) +
mapview(flooding,
color="darkblue",
alpha.regions= 0.5,
layer.name="0.Flooding layer") +
mapview(subset_network_in,
color="red",
lwd= 1,
hide = TRUE,
layer.name="1.Network inside the flooding") +
mapview(subset_network_out,
color="yellow",
lwd= 1.2,
hide = TRUE,
layer.name="2.Flooding outside the flooding mask",
popup=popupTable(subset_network_out)) +
mapview(subset_network_outside_flood,
color="lightgreen",
lwd= 1.4,
hide = TRUE,
layer.name="3 & 4. Network on the boundaries",
popup=popupTable(subset_network_outside_flood)) +
mapview(subset_network_post,
color="green",
lwd= 1,
hide =TRUE,
layer.name="5. Uniting network external to the boundires and network from outside",
popup=popupTable(subset_network_post))After obtaining this post-disaster network, pgrouting created the vertices table required to conduct the centrality analysis. Similarly to generating the pre-disaster network, an analysis of the component identified those components more relevant due to its length. Since some of the post-disaster network components had similar length, the table “component_analysis_network_porto_post” stored this information, which after a qualitative inspection determined the components and their nodes that finally composed the post-disaster network.
PostGIS: Creating the post-disaster network
---- 1) Creating a vertices table required for centrality analysis
SELECT pgr_createverticesTable('porto_alegre_net_post_v5');
---- 2) Obtaining components and their nodes to be used later as a filter.
CREATE TABLE component_analysis_network_porto_post AS
WITH porto_alegre_net_component_post AS (
SELECT
*
FROM
pgr_strongComponents('SELECT id,
source,
target,
cost
FROM
porto_alegre_net_post_v5')),
porto_alegre_net_component_geom_post AS (
SELECT
net.*,
net_geom.the_geom
FROM
porto_alegre_net_component_post AS net
JOIN
porto_alegre_net_post_v5 AS net_geom
ON
net.node = net_geom.source)
SELECT
component,
st_union(the_geom) AS the_geom,
st_length(st_union(the_geom)::geography)::int AS length
FROM
porto_alegre_net_component_geom_post
GROUP BY component
ORDER BY length DESC;
--- Summarising component
CREATE TABLE components_network_post AS
WITH porto_alegre_net_component_post AS (
SELECT
*
FROM
pgr_strongComponents('SELECT
id,
source,
target,
cost
FROM
porto_alegre_net_post_v5')),
--- 3) Calculating the largest component from the network
largests_component_net_post AS (
SELECT
component,
the_geom,
length::int
FROM
component_analysis_network_porto_post)
SELECT * FROM largests_component_net_post;
---- Visualizing which are more important
CREATE TABLE main_components_post AS
SELECT
*
FROM
components_network_post
WHERE
component IN (21,14,5187);
-------------- Remember to justify why 5
CREATE TABLE prueba_largest_network_post AS
WITH porto_alegre_net_component_post AS (
SELECT
*
FROM
pgr_strongComponents('SELECT
id,
source,
target,
cost
FROM
porto_alegre_net_post_v5')),
--- Calculate the largest component from the network
largest_component_net_post AS (
SELECT
component
FROM
component_analysis_network_porto_post
LIMIT 5),
--- Using the largest component from the network to filter
largeset_component_network_porto_post AS (
SELECT
*
FROM
porto_alegre_net_component_post,
largest_component_net_post
WHERE
porto_alegre_net_component_post.component = largest_component_net_post.component)
SELECT
net_multi_component.*
FROM
porto_alegre_net_post_v5 AS net_multi_component,
largeset_component_network_porto_post AS net_largest_component
WHERE
net_multi_component.source IN (net_largest_component.node);3.3 Measuring centrality on networks
The centrality metrics used to determine the importance of each road segment or hospitals in the network were the edge betweenness centrality and closeness centrality respectively.
- The closenesss centrality defined as a measure of how central to other vertices is a vertex (Kolaczyk and Csárdi 2014). It is obtained calculating the average shortest path from a node v to all other nodes in the network (Eq 1) (Florath, Chanussot, and Keller 2024).
\[ \text{CN}(v) = \frac{n - 1}{\sum_{w = 1}^{n - 1} d(w, v)} \]
where d(w,v) is the shortest path distance and n-1 is | the number of nodes reachable from v. In this case, | instead of using the distance to determine how central | | each hospital in the AoI was,it was the cost provided by | ORS. A higher value indicated a faster access to the | hospital, while a large decrease after the flooding event | indicated high vulnerability.
- The betweenness centrality assess the significance of roads in a network by counting the number of shortest paths that pass through this node. The most common definition of the betweenness centrality was introduced by Freeman (Eq 2) (Freeman 1977).
\[ c_{B}(v) = \sum_{\substack{s \neq t \neq v \\ s,t \in V}} \frac{\sigma(s,t|v)}{\sigma(s,t)} \]
where σ(s,t|v) is the total number of shortest paths between s and t that pass through v, and σ(s,t) is the total number of shortest paths between s and t (regardless of whether or not they pass through v). In the event that shortest paths are unique, cB(v) just counts the number of shortest paths going through v (Kolaczyk and Csárdi 2014). In this case, edges are used instead of vertices. Those roads that are frequently part of shortest paths had higher values. This metric was used before to assess the accessibility of critical amenities before and during floodings (Phua et al. 2024 ; Petricola et al. 2022 ; Gangwal et al. 2023).
3.3.1 Generating Origin-Destination matrix
The volume of people is modeled using a traffic matrix or origin-destination (OD) matrix denoted by \(Z = [Z_{ij}]\) , where \(Z_{ij}\) represents the total volume of people flowing from a starting point \(i\) to a ending point \(j\) in a given period of time. For this study case, these generated points are then snapped into the ORS graph network where the variables “fromid” and “toid” are the origin and destination respectively. A naive approach sampled these OD using a regular distribution, while another approach used the built-up density as weight to take more samples where there were more buildings. The motivation of choice were previous studies that suggested using to consider origin-destination distributions to avoid being overly simplistic (Coles et al. 2017).
3.3.1.1 Sampling using regular distribution
The function “I_Grid_Point_Series” created a series of regular points that represented the OD matrix given an area geometry, and the distance for the X-axis and Y-axis in angle degrees. After this, a table stored 1258 sample points generated on the AoI with a distance of 0.01 º between each sample. Lastly, the application of two indexes improved further queries on this new table. This was recommended because these points were outside the network requiring snapping, which is a spatial operation with relatively high computational costs. Apart from indexing the geometry column and the id, the query is constrained to a buffer of 0.01º to reduce computational costs and the one multipoint geometry is converted into 1258 simple points.
PostGIS: Creating a function to sample regularly
--- 1) Creating the function that sample OD regularly:
CREATE OR REPLACE FUNCTION I_Grid_Point_Series(geom geometry, x_side decimal, y_side decimal, spheroid boolean default false)
RETURNS SETOF geometry AS $BODY$
DECLARE
x_max decimal;
y_max decimal;
x_min decimal;
y_min decimal;
srid integer := 4326;
input_srid integer;
x_series DECIMAL;
y_series DECIMAL;
BEGIN
CASE st_srid(geom) WHEN 0 THEN
geom := ST_SetSRID(geom, srid);
RAISE NOTICE 'SRID Not Found.';
ELSE
RAISE NOTICE 'SRID Found.';
END CASE;
CASE spheroid WHEN false THEN
RAISE NOTICE 'Spheroid False';
else
srid := 900913;
RAISE NOTICE 'Spheroid True';
END CASE;
input_srid:=st_srid(geom);
geom := st_transform(geom, srid);
x_max := ST_XMax(geom);
y_max := ST_YMax(geom);
x_min := ST_XMin(geom);
y_min := ST_YMin(geom);
x_series := CEIL ( @( x_max - x_min ) / x_side);
y_series := CEIL ( @( y_max - y_min ) / y_side );
RETURN QUERY
SELECT st_collect(st_setsrid(ST_MakePoint(x * x_side + x_min, y*y_side + y_min), srid)) FROM
generate_series(0, x_series) as x,
generate_series(0, y_series) as y
WHERE st_intersects(st_setsrid(ST_MakePoint(x*x_side + x_min, y*y_side + y_min), srid), geom);
END;
$BODY$ LANGUAGE plpgsql IMMUTABLE STRICT;
--- 2) Using this function to create the sampling table
CREATE TABLE regular_point_od AS (
WITH multipoint_regular AS(
select
I_Grid_Point_Series(geom, 0.037,0.037, false) AS geom
from porto_alegre_bbox as geom),
point_regular AS(
SELECT
st_setsrid((st_dump(geom)).geom, 4326)::geometry(Point, 4326) AS geom
FROM multipoint_regular)
SELECT
row_number() over() AS id,
geom
FROM
point_regular);
--- 3) Applying indexes to increase performance
CREATE INDEX idx_regular_point_od_geom ON regular_point_od USING GIST (geom);
CREATE INDEX idx_regular_point_od_id ON regular_point_od USING btree(id);3.3.1.2 Sampling using weighted distribution
Currently sampling the OD matrix using a weighted distribution is carried out using R. An aliquot of 2728 points is taken from the total size of the sample population of 2.728.133, which represented a 1% of this total. The function spatSample from the terra library took this sample based on the GHS-Built-V raster and the results are stored directly in the PostgreSQL database using the DBI library.
R: Weighted sampling based on the built up density
# Import data
## raster
buildings <- terra::rast('/home/ricardo/HeiGIT-Github/do_not_push_too_large/GHS_BUILT_V_E2020_GLOBE_R2023A_54009_100_V1_0/GHS_BUILT_V_E2020_GLOBE_R2023A_54009_100_V1_0.tif')
pop_ghs <- 2728
## AoI
aoi_bbox <- sf::read_sf('/home/ricardo/HeiGIT-Github/data_required_porto_alegre/porto_alegre_bbox_derived.geojson')
## reproject for clipping
aoi_bbox_reproj <- aoi_bbox |> st_transform(crs(buildings)) |> as_Spatial()
build_cropped <- crop(buildings, aoi_bbox_reproj)
## reproject for sampling
build_4326 <- terra::project(build_cropped, crs(aoi_bbox))
## weighted sampling
od <- spatSample(build_cropped, pop_ghs, "weights", as.points=TRUE, ) |> st_as_sf() |> st_transform(4326)
names(od)[1] <- 'building'
DBI::dbWriteTable(connection,
DBI::Id(schema = "public", table = "od_2728"),
od)After creating an ID for the samples, a neighbor nearest function snapped these points into the closest node of the network. Subsequently, two table subset stored a subset of 100 points for origin and destination due to the path computation costs, since the costs fom the Dijkstra algorithm used in pgrouting are reported as very high (Brandes 2001). Indexes applied on these created tables that contained the OD matrix speed up further queries. This sampling process repeated twice for the pre-flooding and post-flooding scenario generated the OD matrix required to assess the centrality of both networks.
PostGIS: Snapping samples to the closest node
--- 0) Creating an ID column
ALTER TABLE od_2728
ADD COLUMN id serial PRIMARY KEY;
----1: Pre flooding event
--- 1.1) Snapping all the points based on building density to the closest vertices within the network
CREATE TABLE od_2728_snapped AS
SELECT DISTINCT ON (net.id)
pt.id AS pt_id,
net.id AS net_id,
net.the_geom
FROM
(select *
FROM
od_2728 as pt) as pt
CROSS JOIN
LATERAL (SELECT
*
FROM porto_alegre_net_largest_vertices_pgr AS net
ORDER BY net.the_geom <-> pt.geometry
LIMIT 1) AS net;
--- 1.2) Limiting to 100 origin points in the pre flooding event
CREATE TABLE weight_sampling_100_origin AS
WITH porto_100_origin AS (
SELECT
*
FROM
od_2728_snapped
ORDER BY random() LIMIT 100)
SELECT * FROM porto_100_origin;
--- 1.3) Limiting to 100 destination in the pre flooding event
CREATE TABLE weight_sampling_100_destination AS
WITH porto_100_destination AS (
SELECT
*
FROM
od_2728_snapped
ORDER BY random() LIMIT 100)
SELECT * FROM porto_100_destination;
--- Indeces on origin
CREATE INDEX weight_sampling_100_origin_idx_pt_id ON weight_sampling_100_origin USING btree(pt_id);
CREATE INDEX weight_sampling_100_origin_idx_net_id ON weight_sampling_100_origin USING btree(net_id);
CREATE INDEX weight_sampling_100_origin_idx_the_geom ON weight_sampling_100_origin USING gist(the_geom);
----- A) Indexes, clustering and vacuum
--- Indexes on destination
CREATE INDEX weight_sampling_100_destination_idx_pt_id ON weight_sampling_100_destination USING btree(pt_id);
CREATE INDEX weight_sampling_100_destination_idx_net_id ON weight_sampling_100_destination USING btree(net_id);
CREATE INDEX weight_sampling_100_destination_idx_the_geom ON weight_sampling_100_destination USING gist(the_geom);
---- Cluster
CLUSTER porto_alegre_net_largest USING idx_porto_alegre_net_largest_geom;
---- Vacuum clean
VACUUM(full, ANALYZE) weight_sampling_100_origin;
VACUUM(full, ANALYZE) weight_sampling_100_destination;
VACUUM(full, ANALYZE) porto_alegre_net_largest;
----
---- 2) Post flooding scenario:
--- 2.1) Snapping 2728 points to post-scenario network
CREATE TABLE od_2728_snapped_post AS
SELECT DISTINCT ON (net.id)
pt.id AS pt_id,
net.id AS net_id,
net.the_geom
FROM
(select *
FROM
od_2728 as pt) as pt
CROSS JOIN
LATERAL (SELECT
*
FROM prueba_largest_network_post_vertices_pgr AS net
ORDER BY net.the_geom <-> pt.geometry
LIMIT 1) AS net;
--- 2.2) Creating 100 origin samples from the snapped points post-scenario
CREATE TABLE weight_sampling_100_origin_post AS
WITH porto_100_origin AS (
SELECT
*
FROM
od_2728_snapped_post
ORDER BY random() LIMIT 100)
SELECT * FROM porto_100_origin;
--- 2.3) Creating 100 destination from the snapped points post-scenario
CREATE TABLE weight_sampling_100_destination_post AS
WITH porto_100_destination AS (
SELECT
*
FROM
od_2728_snapped_post
ORDER BY random() LIMIT 100)
SELECT * FROM porto_100_destination;
--- B) Indeces on origin
CREATE INDEX weight_sampling_100_origin_idx_pt_id ON weight_sampling_100_origin USING btree(pt_id);
CREATE INDEX weight_sampling_100_origin_idx_pt_id ON weight_sampling_100_origin USING btree(net_id);
CREATE INDEX weight_sampling_100_origin_idx_the_geom ON weight_sampling_100_origin USING gist(the_geom);
--- Indeces on destination
CREATE INDEX weight_sampling_100_destination_post_idx_pt_id ON weight_sampling_100_destination_post USING btree(pt_id);
CREATE INDEX weight_sampling_100_destination_post_idx_net_id ON weight_sampling_100_destination_post USING btree(net_id);
CREATE INDEX weight_sampling_100_destination_post_idx_the_geom ON weight_sampling_100_destination_post USING gist(the_geom);
---- Indexes on origin
CREATE INDEX weight_sampling_100_origin_post_idx_pt_id ON weight_sampling_100_origin_post USING btree(pt_id);
CREATE INDEX weight_sampling_100_origin_post_idx_net_id ON weight_sampling_100_origin_post USING btree(net_id);
CREATE INDEX weight_sampling_100_origin_post_idx_the_geom ON weight_sampling_100_origin_post USING gist(the_geom);
---- Index on the new network
CREATE INDEX prueba_largest_network_post_idx_GEOM ON prueba_largest_network_post USING gist(the_geom);
CREATE INDEX prueba_largest_network_post_idx_id ON prueba_largest_network_post USING btree(id);
CREATE INDEX prueba_largest_network_post_idx_target ON prueba_largest_network_post USING btree(target);
CREATE INDEX prueba_largest_network_post_idx_source ON prueba_largest_network_post USING btree(source);
CREATE INDEX prueba_largest_network_post_idx_cost ON prueba_largest_network_post USING btree(cost);
---- Cluster
CLUSTER prueba_largest_network_post USING prueba_largest_network_post_idx_GEOM;
---- Vacuum clean
VACUUM(full, ANALYZE) weight_sampling_100_origin;
VACUUM(full, ANALYZE) weight_sampling_100_destination;
VACUUM(full, ANALYZE) porto_alegre_net_largest; 3.3.1.3 Selecting point of interest (Hospitals)
The bounding box containing the GHS settlement that intersected with Porto Alegre filtered the Hospitals from Rio Grande do Sul. Similarly to previous sampling, a closest neighbor query snapped the location of these hospitals to the closest vertices of the network. Hospitals and other healthcare facilities were the objects of previous studies focused on accessibility (Geldsetzer et al. 2020 ; Sushma and Reddy 2021). The following query provided the table of healthcare facilities affected by the flooding, which were the destination of the OD matrix and required to assess their accessibility.
PostGIS: Selecting hospistals in the AoI and snapping
--- Creating a table with the bounding box that contains Porto Alegre + GHS
CREATE TABLE porto_alegre_bbox AS
WITH porto_alegre_ghs AS(
SELECT
ghs.*
FROM
urban_center_4326 AS ghs
JOIN
nuts
ON
st_intersects(nuts.geom, ghs.geom)
WHERE
nuts.shapename = 'Porto Alegre'),
--- Bounding Box that contained the GHS in Porto Alegre
porto_alegre_ghs_bbox AS(
SELECT
st_setsrid(st_extent(geom),4326) as geom_bbox
FROM
porto_alegre_ghs)
SELECT * FROM porto_alegre_ghs_bbox
---Use the bounding box to select hospitals
CREATE TABLE hospital_rs_node_v2 AS
WITH hospital_rs_porto AS (
SELECT
h.*
FROM
hospitals_bed_rs AS h,
porto_alegre_bbox bbox
WHERE st_intersects(h.geom, bbox.geom_bbox))
SELECT DISTINCT ON (h.cd_cnes)
cd_cnes,
ds_cnes,
f.id,
f.the_geom <-> h.geom AS distance,
h.geom AS geom_hospital,
f.the_geom AS geom_node
FROM hospital_rs_porto h
---- Snapping the hospitals to the closest vertices in the network
LEFT JOIN LATERAL
(SELECT
id,
the_geom
FROM porto_alegre_net_largest_vertices_pgr AS net
ORDER BY
net.the_geom <-> h.geom
LIMIT 1) AS f ON true
---- Create index to optimize fuerther queries
CREATE INDEX idx_hospital_rs_node_v2 ON hospital_rs_node_v2 USING btree(id);3.3.2 Carrying out centrality analysis
The graph network obtained from OpenRouteService provided the vertices, edges and weight required for the function pgr_dijkstra. The variable toid and fromid represented the source and target, while weight was the cost. After including this information in the function, the OD matrix included as two arrays completed the required inputs to run the dijkstra algorithm. The table 1 shown the data from this graph network without including the geometry.
The table generated included the ogc_fid variable making possible to join original geometry from the graph network table. This table contained all the shortest paths, where on the one hand, the variables start_vid and end_vid were the source (fromid) and destination (toid) from the original OD matrix. On the other hand, edge indicated the edge id from the graph network.
3.3.2.1 Assessing network centrality
The aggregated count of these shortest path determined the centrality of each segment. A further processing required was to use group these values by the bidirectid, obtaining the final betweenness centrality value. This process applied to the pre-disaster and post-disaster network using the two OD matrix allowed to compare the change of the betweenness centrality.
PostGIS: Calculating edge betweenness centrality on the pre-disaster network
--- 1) Pre-disaster network
--- 1.1) Creating centrality
CREATE TABLE centrality_100_100_dijkstra AS
SELECT b.id,
b.the_geom,
count(the_geom) as centrality
FROM pgr_dijkstra('SELECT id,
source,
target,
cost
FROM porto_alegre_net_largest',
ARRAY(SELECT net_id AS start_id FROM weight_sampling_100_origin ),
ARRAY(SELECT net_id AS end_id FROM weight_sampling_100_destination ),
directed := TRUE) j
left JOIN porto_alegre_street_united AS b
ON j.edge = b.id
GROUP BY b.id, b.the_geom
ORDER BY centrality DESC;
---- Adding the bidirectid by joining the dijkstra table with the original
CREATE TABLE centrality_weighted_100_bidirect AS
SELECT t1.*,
t2."bidirectid"
FROM
centrality_100_100_dijkstra t1
JOIN
porto_alegre_net_largest t2
ON
t1.id = t2.id;
--- The final product requries 79941
select max("bidirectid") from centrality_weighted_100_bidirect;
create sequence bididirect_id_weight start 79941;
update centrality_weighted_100_bidirect
set "bidirectid" = nextval('bididirect_id_weight')
where "bidirectid" is null ;
---- verify
select count(*)
from centrality_weighted_100_bidirect
where "bidirectid" is null; --- 0
----
create table centrality_weighted_100_bidirect_group as
select
"bidirectid",
sum(centrality) as centrality
from centrality_weighted_100_bidirect
group by "bidirectid"; --- this sum the centrality for duplicated bidirect id
---
---- now recover the id
create table centrality_weighted_100_bidirect_group_id as
select t1.*, t2.id
from centrality_weighted_100_bidirect_group t1
join centrality_weighted_100_bidirect t2
on t1."bidirectid" = t2."bidirectid";
---- add geometries
create table centrality_weighted_100_bidirect_cleaned as
select t1.*,
t2.the_geom,
t2.target,
t2.source,
t2.cost,
t2."unidirectid"
from
centrality_weighted_100_bidirect_group_id t1
join
porto_alegre_net_largest t2
on
t1.id = t2.id;
--- The final product is: centrality_weighted_100_bidirect_cleaned
--- 2) Post scenario
----routing
CREATE TABLE centrality_100_100_dijkstra_post AS
SELECT b.id,
b.the_geom,
count(the_geom) as centrality
FROM pgr_dijkstra('SELECT id,
source,
target,
cost
FROM prueba_largest_network_post',
ARRAY(SELECT net_id AS start_id FROM weight_sampling_100_origin_post ),
ARRAY(SELECT net_id AS end_id FROM weight_sampling_100_destination_post ),
directed := TRUE) j
left JOIN prueba_largest_network_post AS b
ON j.edge = b.id
GROUP BY b.id, b.the_geom
ORDER BY centrality DESC;
---- Adding the bidirectid by joining the dijkstra table with the original
CREATE TABLE centrality_weighted_100_bidirect_post AS
SELECT t1.*,
t2."bidirectid"
FROM
centrality_100_100_dijkstra_post t1
JOIN
prueba_largest_network_post t2
ON
t1.id = t2.id;
--- The final product requries 79918
select max("bidirectid") from centrality_weighted_100_bidirect_post; ---79918
create sequence bididirect_id_weight_post start 79918;
update centrality_weighted_100_bidirect_post
set "bidirectid" = nextval('bididirect_id_weight_post')
where "bidirectid" is null ;
---- verify
select count(*)
from centrality_weighted_100_bidirect_post
where "bidirectid" is null; --- 0
----
create table centrality_weighted_100_bidirect_group_post as
select
"bidirectid",
sum(centrality) as centrality
from centrality_weighted_100_bidirect_post
group by "bidirectid"; --- this sum the centrality for duplicated bidirect id
---
---- now recover the id
create table centrality_weighted_100_bidirect_group_post_id as
select t1.*, t2.id
from centrality_weighted_100_bidirect_group_post t1
join centrality_weighted_100_bidirect_post t2
on t1."bidirectid" = t2."bidirectid";
---- add geometries
create table centrality_weighted_100_bidirect_cleaned_post as
select t1.*,
t2.the_geom,
t2.target,
t2.source,
t2.cost,
t2."unidirectid"
from
centrality_weighted_100_bidirect_group_post_id t1
join
prueba_largest_network_post t2
on
t1.id = t2.id; 3.3.2.2 Assessing hospitals centrality
A subset of 474 points from the weighted sampling was the origin table (source or fromid), while 22 hospitals within the AoI were the destination table (target or toid). Similarly to the network, counting the number of geometries returned the centrality value. However, for the hospital centrality centrality values were also grouped by the destination, named as end_vid. Applying this process to the pre-network and post-network with their respective OD matrix allowed us to assess the change of centrality on the healthcare facilities.
Show the code
------ PRE-EVENT
---- Based on a max of 100*100 / 22 = 454
SELECT count(*) FROM hospital_rs_node_v2; --- 22 POI: Hospitals
----- Create origin
CREATE TABLE weight_sampling_454_origin AS
WITH porto_454_origin AS (
SELECT
*
FROM
od_2728_snapped
ORDER BY random()
LIMIT 454)
SELECT * FROM porto_454_origin;
--- Create destinations in this case hospitals
CREATE TABLE hospital_rs_destination AS
SELECT
cd_cnes,
ds_cnes,
id,
geom_node
FROM
hospital_rs_node_v2; --- 22 POI: Hospitals
---- Create hospitald destinations from closeness
CREATE TABLE hospital_rs_destination AS
WITH clossness_hospital_porto_id AS (
SELECT
n.*,
v.id
FROM
clossness_hospital_porto AS n
JOIN
porto_alegre_net_largest_vertices_pgr AS v
ON st_intersects(n.geom_node, v.the_geom))
SELECT
cd_cnes,
ds_cnes,
id,
closeness,
geom_node
FROM
clossness_hospital_porto_id;
---- Create index for origin
CREATE INDEX weight_sampling_454_origin_net_id ON weight_sampling_454_origin USING hash(net_id);
CREATE INDEX weight_sampling_454_origin_geom ON weight_sampling_454_origin USING gist(the_geom);
---- Create index for destination
CREATE INDEX hospital_rs_destination_net_id ON hospital_rs_destination USING btree(id);
CREATE INDEX hospital_rs_destination_geom ON hospital_rs_destination USING gist(geom_node);
---- Cluster
CLUSTER porto_alegre_net_largest USING idx_porto_alegre_net_largest_geom;
---- Vacuum clean
VACUUM(full, ANALYZE) weight_sampling_454_origin;
VACUUM(full, ANALYZE) hospital_rs_destination;
VACUUM(full, ANALYZE) porto_alegre_net_largest;
---- Running the query
EXPLAIN ANALYZE
CREATE TABLE centrality_424_hospitals_porto_end_id_centrality AS
SELECT
b.vid,
j.end_id,
b.the_geom,
count(the_geom) as centrality
FROM pgr_dijkstra('SELECT id,
source,
target,
cost
FROM porto_alegre_net_largest',
ARRAY(SELECT net_id AS origin_id FROM weight_sampling_454_origin),
ARRAY(SELECT id AS destination_id FROM hospital_rs_destination),
directed := TRUE) j
left JOIN porto_alegre_net_largest AS b
ON j.edge = b.id
GROUP BY b.id, j.end_vid, b.the_geom
ORDER BY centrality DESC;
---- Group by end_vid that represent destination
select * from hospital_rs_destination ;
SELECT * FROM centrality_424_hospitals_porto_end_id_centrality;
SELECT
centrality.end_vid,
hospitals.cd_cnes,
hospitals.ds_cnes,
count(centrality.the_geom)::int AS sum_centrality,
max(st_length(centrality.the_geom::geography))::int AS length
FROM
centrality_424_hospitals_porto_end_id_centrality AS centrality
LEFT JOIN
hospital_rs_destination AS hospitals ON centrality.end_vid = hospitals.id
GROUP BY end_vid, cd_cnes, ds_cnes;
### Post-scenario
SELECT count(*) FROM hospital_rs_node_v2; --- 22 POI: Hospitals
----- Create origin
CREATE TABLE weight_sampling_454_origin_post AS
WITH porto_454_origin_post AS (
SELECT
*
FROM
od_2728_snapped_post
ORDER BY random()
LIMIT 454)
SELECT * FROM porto_454_origin_post;
--- Create destinations in this case hospitals
CREATE TABLE hospital_rs_destination AS
SELECT
cd_cnes,
ds_cnes,
id,
geom_node
FROM
hospital_rs_node_v2; --- 22 POI: Hospitals
---- Create hospitald destinations from closeness
CREATE TABLE hospital_rs_destination AS
WITH clossness_hospital_porto_id AS (
SELECT
n.*,
v.id
FROM
clossness_hospital_porto AS n
JOIN
porto_alegre_net_largest_vertices_pgr AS v
ON st_intersects(n.geom_node, v.the_geom))
SELECT
cd_cnes,
ds_cnes,
id,
closeness,
geom_node
FROM
clossness_hospital_porto_id;
---- Create index for origin
CREATE INDEX weight_sampling_454_origin_net_id ON weight_sampling_454_origin_post USING hash(net_id);
CREATE INDEX weight_sampling_454_origin_geom ON weight_sampling_454_origin_post USING gist(the_geom);
---- Create index for destination
CREATE INDEX hospital_rs_destination_net_id ON hospital_rs_destination USING btree(id);
CREATE INDEX hospital_rs_destination_geom ON hospital_rs_destination USING gist(geom_node);
---- Cluster
CLUSTER porto_alegre_net_largest USING idx_porto_alegre_net_largest_geom;
---- Vacuum clean
VACUUM(full, ANALYZE) weight_sampling_454_origin_post;
VACUUM(full, ANALYZE) hospital_rs_destination;
VACUUM(full, ANALYZE) prueba_largest_network_post;
---- Running the query
EXPLAIN ANALYZE
CREATE TABLE centrality_424_hospitals_porto_end_id_centrality_post AS
SELECT
b.ogc_fid,
j.end_vid,
b.the_geom,
count(the_geom) as centrality
FROM pgr_dijkstra('SELECT ogc_fid AS id,
fromid AS source,
toid AS target,
weight AS cost
FROM prueba_largest_network_post',
ARRAY(SELECT net_id AS origin_id FROM weight_sampling_454_origin_post),
ARRAY(SELECT id AS destination_id FROM hospital_rs_destination),
directed := TRUE) j
left JOIN prueba_largest_network_post AS b
ON j.edge = b.ogc_fid
GROUP BY b.ogc_fid, j.end_vid, b.the_geom
ORDER BY centrality DESC;
---- Group by end_vid that represent destination
CREATE TABLE centrality_424_hospitals_porto_end_id_centrality_post_group AS
SELECT
centrality.end_vid,
hospitals.cd_cnes,
hospitals.ds_cnes,
max(centrality.centrality)::int AS max_centrality,
max(st_length(centrality.the_geom::geography))::int AS length
FROM
centrality_424_hospitals_porto_end_id_centrality_post AS centrality
LEFT JOIN
hospital_rs_destination AS hospitals ON centrality.end_vid = hospitals.id
GROUP BY end_vid, cd_cnes, ds_cnes;3.3.3 Carrying out accessibility analysis
Closenness
3.3.3.1 Asessing hospitals accessibility
The function pgr_dijkstraCostMatrix calculated the sum of the costs of the shortest path for pair combination of nodes in the graph. Grouping the aggregated costs of these cost matrix by origin returned the closeness metrics. Lastly, using the ID of the vertices from the hospital tables the closeness values are included obtaining the most affected healthcare facilities
PostGIS: Calculating closeness for each hospital
--- POST-EVENT
CREATE TABLE weight_sampling_454_origin_post AS
WITH porto_454_origin_post AS (
SELECT
*
FROM
od_2728_snapped_post
ORDER BY random()
LIMIT 454)
SELECT * FROM porto_454_origin_post;
---- Create index for origin
CREATE INDEX weight_sampling_454_origin_post_net_id ON weight_sampling_454_origin_post USING hash(net_id);
CREATE INDEX weight_sampling_454_origin_post_geom ON weight_sampling_454_origin_post USING gist(the_geom);
---- Running the query
---- Group by end_vid that represent destination
EXPLAIN ANALYZE
CREATE TABLE centrality_424_hospitals_porto_end_id_centrality_post AS
SELECT
b.id,
j.end_vid,
b.the_geom,
count(the_geom) as centrality
FROM pgr_dijkstra('SELECT id,
source,
target,
cost
FROM prueba_largest_network_post',
ARRAY(SELECT net_id AS origin_id FROM weight_sampling_454_origin_post),
ARRAY(SELECT id AS destination_id FROM hospital_rs_destination),
directed := TRUE) j
LEFT JOIN prueba_largest_network_post AS b
ON j.edge = b.id
GROUP BY b.id, j.end_vid, b.the_geom
ORDER BY centrality DESC;
---- Pre-Event
CREATE TABLE clossness_hospital_porto AS
WITH dijkstra_cost AS (
SELECT * FROM pgr_dijkstraCostMatrix(
'SELECT id, source, target, cost FROM porto_alegre_net_largest',
(SELECT array_agg(id)
FROM porto_alegre_net_largest_vertices_pgr
WHERE id IN (SELECT id FROM hospital_rs_node_v3)),
true)),
closeness AS (
SELECT dc.start_vid,
sum(agg_cost)::int AS closeness
FROM dijkstra_cost dc
GROUP BY dc.start_vid
ORDER BY closeness DESC)
SELECT
h.cd_cnes,
h.ds_cnes,
c.closeness,
h.distance,
h.geom_node,
h.geom_hospital
FROM
closeness AS c
LEFT JOIN
hospital_rs_node_v3 AS h ON c.start_vid = h.id;
--- Post event
CREATE TABLE clossness_hospital_porto_post AS
WITH dijkstra_cost AS (
SELECT * FROM pgr_dijkstraCostMatrix(
'SELECT id, source, target, cost FROM prueba_largest_network_post',
(SELECT array_agg(id)
FROM prueba_largest_network_post_vertices_pgr
WHERE id IN (SELECT id FROM hospital_rs_node_v3)),
true)),
closeness AS (
SELECT dc.start_vid,
sum(agg_cost)::int AS closeness
FROM dijkstra_cost dc
GROUP BY dc.start_vid
ORDER BY closeness DESC)
SELECT
h.cd_cnes,
h.ds_cnes,
c.closeness,
h.distance,
h.geom_node,
h.geom_hospital
FROM
closeness AS c
LEFT JOIN
hospital_rs_node_v3 AS h ON c.start_vid = h.id;
---- Add centrality from post-event to pre-event
CREATE TABLE hospitals_closeness_both AS
SELECT
pre.cd_cnes,
pre.ds_cnes,
pre.closeness AS closeness_pre,
coalesce(post.closeness,0) AS closeness_post,
pre.geom_node,
pre.geom_hospital
FROM
clossness_hospital_porto AS pre
LEFT JOIN
clossness_hospital_porto_post AS post ON pre.cd_cnes = post.cd_cnes3.3.4 Assesing vulnerability based on socioeconomic indicators
3.4 Validating results
Nicht wichtig, vieliecht weg lassen.
---- add ID
ALTER TABLE od_77763
ADD COLUMN id serial;
---- Rename the column name
ALTER TABLE od_77763
rename "GHS_BUILT_V_E2020_GLOBE_R2023A_54009_100_V1_0"
to "build";
---- create spatial index
CREATE INDEX idx_od_77763_geom ON od_77763
USING gist(geometry);
CREATE INDEX idx_od_77763_id on weighted_sampling
USING btree(id);
CREATE INDEX idx_od_77763_geom_build on weighted_sampling
USING btree("build");
---- The current total is 77763
----
CREATE TABLE od_40420_snapped_origin AS
SELECT DISTINCT ON (net.id)
pt.id AS pt_id,
net.id AS net_id,
net.the_geom
FROM
(select *
FROM
od_77763 as pt) as pt
CROSS JOIN
LATERAL (SELECT
*
FROM porto_alegre_net_largest_vertices_pgr AS net
ORDER BY net.the_geom <-> pt.geometry
LIMIT 1) AS net;
----
CREATE TABLE od_40420_snapped_destination AS
SELECT DISTINCT ON (net.id)
pt.id AS pt_id,
net.id AS net_id,
net.the_geom
FROM
(select *
FROM
od_77763 as pt) as pt
CROSS JOIN
LATERAL (SELECT
*
FROM porto_alegre_net_largest_vertices_pgr AS net
ORDER BY net.the_geom <-> pt.geometry
LIMIT 1) AS net;